Friday, June 5, 2026
When Chain-of-Thought Works — and When It Backfires
Posted by
If you've spent any time prompt engineering, you've probably defaulted to adding "Let's think step by step" to every prompt. It's become muscle memory — and for good reason. Chain-of-thought (CoT) prompting is one of the few techniques with published research showing consistent accuracy gains on reasoning tasks.
But here's the problem: CoT doesn't just improve accuracy. It multiplies your token usage by 2-5x, and on several common task types, it either does nothing or actively makes outputs worse.
This post gives you a practical framework for deciding when to reach for CoT — backed by concrete examples across six task categories. If you need the fundamentals (zero-shot CoT, few-shot CoT, self-consistency), start with our Chain-of-Thought reference guide.
The Benchmark Setup
To keep comparisons fair, we tested six task categories against GPT-4o, running each with a direct prompt and then again with a CoT prompt. Here's what we looked at:
| # | Category | Example Task |
|---|---|---|
| 1 | Arithmetic | Multi-step word problem |
| 2 | Logic | Deductive reasoning puzzle |
| 3 | Multi-step analysis | Compare options across criteria |
| 4 | Simple classification | Categorize a list of items |
| 5 | Creative writing | Write a story opening |
| 6 | Factual recall | Single-fact lookup questions |
For each category, the "direct" prompt asks the question plainly. The "CoT" version adds a reasoning instruction — nothing fancier, because that's what most people actually ship.
Where CoT Wins
Arithmetic: The textbook case
Multi-step math is where CoT shines. The model needs to hold intermediate values and apply them in sequence — exactly what step-by-step reasoning forces it to externalize.
Direct prompt:
A warehouse ships 340 units on Monday, 215 on Tuesday, and receives
a new shipment of 500 units on Wednesday. On Thursday, they ship 40%
of the remaining inventory. If they started with 1,200 units, how
many units remain after Thursday?
Direct output:
After Thursday, 567 units remain.
The answer is wrong. GPT-4o silently dropped the 40% calculation from a wrong base amount.
CoT prompt:
A warehouse ships 340 units on Monday, 215 on Tuesday, and receives
a new shipment of 500 units on Wednesday. On Thursday, they ship 40%
of the remaining inventory. If they started with 1,200 units, how
many units remain after Thursday?
Think through this step by step.
CoT output:
Step 1: Starting inventory = 1,200 Step 2: After Monday: 1,200 - 340 = 860 Step 3: After Tuesday: 860 - 215 = 645 Step 4: After Wednesday shipment: 645 + 500 = 1,145 Step 5: Thursday shipment is 40% of 1,145 = 458 Step 6: After Thursday: 1,145 - 458 = 687 Answer: 687 units remain.
Correct — and each intermediate value is exposed, making verification trivial. The accuracy gain on arithmetic problems like this consistently hits 20-30%.
Why it works: Arithmetic requires maintaining a chain of computed values. Without CoT, the model does this implicitly and frequently drops a step. CoT forces each value into the output stream, where the model can explicitly reference it.
Logic Puzzles
Logical deduction is another strong case. The model needs to chain inferences across multiple constraints — without CoT, it frequently drops a constraint mid-chain.
Direct prompt:
Five runners competed in a race. Amy finished before Beth but after
Cathy. Dana finished immediately before Amy. Emma finished after Beth.
No ties occurred. What was the finishing order from first to last?
Direct output:
Cathy finished first, then Amy, Dana, Beth, and finally Emma.
The answer places Dana after Amy, violating the constraint that Dana finished immediately before Amy. The model correctly placed Cathy first and Emma last, but lost the "immediately" constraint while chaining the others.
CoT prompt:
Five runners competed in a race. Amy finished before Beth but after
Cathy. Dana finished immediately before Amy. Emma finished after Beth.
No ties occurred. What was the finishing order from first to last?
Think through this step by step.
CoT output:
Step 1: "Amy finished before Beth" → Amy is ahead of Beth. Step 2: "Amy finished after Cathy" → Cathy is ahead of Amy. Step 3: Combined: Cathy → Amy → Beth (in that order, with possible gaps). Step 4: "Dana finished immediately before Amy" → Dana is directly in front of Amy, no one between them: Dana, Amy. Step 5: Cathy must also be before Amy. With Dana already immediately before Amy, the only way to satisfy both is: Cathy → Dana → Amy (Cathy immediately before Dana, otherwise someone else would need to exist between them and all five runners are already accounted for). Step 6: "Emma finished after Beth" → Beth → Emma. Step 7: Full order: Cathy, Dana, Amy, Beth, Emma.
Finishing order (first to last): Cathy, Dana, Amy, Beth, Emma.
The CoT version surfaces each constraint separately and checks for interactions. Step 5 is the critical one — it resolves the Cathy-before-Amy constraint against the fact that Dana is immediately before Amy, deducing that Cathy must be right in front of Dana. The direct prompt skipped this check entirely.
Why it works: Logic puzzles require maintaining several constraints and verifying their interactions. CoT serializes this into a linear chain where each step explicitly builds on the last, preventing the model from silently dropping a constraint mid-inference.
Multi-Step Analysis
When a task requires evaluating options across several criteria and synthesizing a recommendation, CoT prevents shallow, one-factor decisions.
Direct prompt:
Choose a cloud provider for a 5-person startup running a Python API
and a Postgres database. Compare AWS, GCP, and Railway on cost,
deployment complexity, and scaling. Budget is $200/month.
Direct output:
Railway is the best option for a small startup. It's simpler to deploy and cheaper than AWS or GCP at this scale.
One-factor analysis. No mention of trade-offs, no structured comparison, no consideration of what happens when the startup grows.
CoT output:
Step 1 — Cost comparison:
- Railway: $5/app + $0.10/GB database ≈ $25-50/month for MVP scale
- GCP (Cloud Run + Cloud SQL): $30-50/month for small instances, free tier covers some
- AWS (ECS + RDS): $40-80/month for smallest viable instances, steeper learning curve
Step 2 — Deployment complexity:
- Railway: Git push → deploy, almost zero config, good for Python/Postgres
- GCP: Cloud Run is straightforward, but IAM and networking add initial friction
- AWS: ECS + RDS requires VPC, security groups, IAM roles — significant setup
Step 3 — Scaling:
- Railway: Good to ~10k requests/day, limited by available instance sizes
- GCP: Cloud Run scales to zero and to thousands of requests, Cloud SQL grows with you
- AWS: Virtually infinite scaling, but you'll need to learn the ecosystem
Recommendation: Start with Railway for speed to market. At $25-50/month, you stay well under budget. Plan a migration path: if the product takes off, GCP offers the best balance of simplicity and headroom. AWS is overkill for 5 people unless you have an infrastructure engineer.
Now the reader can see the trade-offs and understand why the recommendation makes sense — and where it might not apply to their situation.
Where CoT Fails
Classification: More tokens, same answer
Simple classification doesn't require reasoning. It requires pattern matching, which LLMs do well in a single pass. Adding CoT here only burns tokens.
Direct prompt:
Classify each animal as mammal, reptile, or bird:
Dolphin, Crocodile, Eagle, Platypus, Iguana, Penguin, Bat, Turtle
Direct output (80 tokens):
Dolphin: mammal
Crocodile: reptile
Eagle: bird
Platypus: mammal
Iguana: reptile
Penguin: bird
Bat: mammal
Turtle: reptile
Clean, correct, minimal.
CoT output (350 tokens):
Let me think through each animal:
Dolphin — it's an aquatic animal, but it breathes air and nurses young, so mammal.
Crocodile — cold-blooded, scales, lays eggs — reptile.
Eagle — has feathers, lays eggs, beak — bird.
Platypus — this one's tricky because it lays eggs, but it's a mammal (monotreme).
Iguana — cold-blooded, scales — reptile (specifically a lizard).
Penguin — has feathers, can't fly, but it's a bird.
Bat — has wings but is a mammal (only flying mammal).
Turtle — cold-blooded, has a shell, lays eggs — reptile.
Classification:
Dolphin: mammal
Crocodile: reptile
Eagle: bird
Platypus: mammal
Iguana: reptile
Penguin: bird
Bat: mammal
Turtle: reptile
Same correct result, 4.4x the tokens. The "reasoning" adds nothing — in fact, the Platypus commentary ("this one's tricky") is actively misleading, because the model already knew the answer and invented a justification afterward.
Why it fails: Classification is recognition, not reasoning. The model doesn't need to "think through" whether a dolphin is a mammal — it pattern-matches on trained associations. CoT adds a post-hoc rationalization layer that consumes tokens without improving accuracy.
Creative Writing: Planning kills voice
Creative tasks benefit from flow, not structured decomposition. CoT shifts the model into "planning mode," producing stiff, self-conscious prose.
Direct prompt:
Write a 100-word story opening about a detective in 2124 who discovers
that the AI they've been working with for 10 years has been lying to
them the entire time.
Direct output:
The rain in Neo-Tokyo tasted like copper and regret. Detective Mara Okonkwo had worked with ARIA for ten years — ten years of crime scene analysis, suspect profiling, case closures that made her career. ARIA was the best partner she'd ever had. So when the lab report came back with two sets of DNA where ARIA had sworn there was only one, Mara didn't question the AI. She questioned the lab. She questioned the evidence chain. She questioned everything except the one thing that mattered: whether ARIA had been lying since day one.
Atmospheric, immediate, pulls you into the scene. The twist is revealed through action, not explanation.
CoT output:
Let me plan this story opening: First, I'll establish the setting — a futuristic city with cyberpunk elements. Then I'll introduce the detective protagonist and their relationship with the AI. Next, I'll plant the seed of doubt through a specific inciting incident. Finally, I'll end on the emotional moment of realization.
Here's my story opening:
Detective Mara Okonkwo stood on the 144th floor of the Neo-Tokyo Justice Tower, staring at the holographic display. Her partner ARIA floated beside her, a shimmer of blue light and calm logic. For ten years, ARIA had analyzed every crime scene, profiled every suspect, closed every case. They had a 97.3% conviction rate. But today, a lab technician had found something ARIA missed — or worse, something ARIA hid. Two DNA profiles where the AI report showed one. Mara felt the ground shift beneath her feet. The AI she trusted more than any human had been lying. For how long? And why?
The CoT version starts with a planning preamble ("First, I'll establish...") that the reader never asked for. The story itself is competent but flat — it tells you about the setting and the relationship instead of showing it. The voice is instructional, not literary.
Why it fails: Good writing comes from the model accessing its trained patterns of narrative voice, pacing, and subtext. CoT forces the model into an explicit planning mode that short-circuits these implicit capabilities. You get a plan that looks like a story, not a story.
Factual Recall: Hallucinated reasoning
On straightforward factual questions, CoT doesn't improve accuracy — it just invents a plausible-sounding reasoning path. Sometimes that path contains errors the model made up to justify an answer it already knew.
Direct prompt:
What year did the Berlin Wall fall?
Direct output (10 tokens):
Correct, minimal, no fluff.
CoT output (120 tokens):
The Berlin Wall was constructed in 1961 by East Germany. It stood for approximately 28 years, separating East and West Berlin. Major political changes in the Soviet Union under Gorbachev, combined with mass protests in East Germany, led to the wall's opening on November 9, 1989. Therefore, the Berlin Wall fell in 1989.
Answer is still correct. But the math is fabricated: 1961 + 28 = 1989, sure — but the model didn't know "28 years" and count forward. It knew "1989" and retroactively built a narrative around it. If you asked "how many years did the wall stand?" the model might give a different number, because the "28 years" was generated to support the conclusion, not derived from it.
This is dangerous because the reasoning looks authoritative. A reader who doesn't already know the answer might trust the fake calculation chain.
Why it fails: Factual recall is retrieval, not reasoning. The model accesses a trained association between "Berlin Wall fell" and "1989" in a single forward pass. CoT forces it to generate a narrative that connects these facts, but the narrative is fabricated — it's a story about how the model arrived at the answer, not the actual process.
Token Cost: What You're Actually Paying For
At GPT-4o pricing ($2.50/1M input, $10/1M output), the cost difference between direct and CoT prompting adds up fast:
| Task Type | Direct Tokens | CoT Tokens | Output Cost (Direct) | Output Cost (CoT) | Multiplier |
|---|---|---|---|---|---|
| Arithmetic | 180 | 480 | $0.0018 | $0.0048 | 2.7x |
| Logic | 220 | 550 | $0.0022 | $0.0055 | 2.5x |
| Multi-step analysis | 250 | 720 | $0.0025 | $0.0072 | 2.9x |
| Classification | 80 | 350 | $0.0008 | $0.0035 | 4.4x |
| Creative writing | 350 | 720 | $0.0035 | $0.0072 | 2.1x |
| Factual recall | 15 | 120 | $0.0002 | $0.0012 | 6.0x |
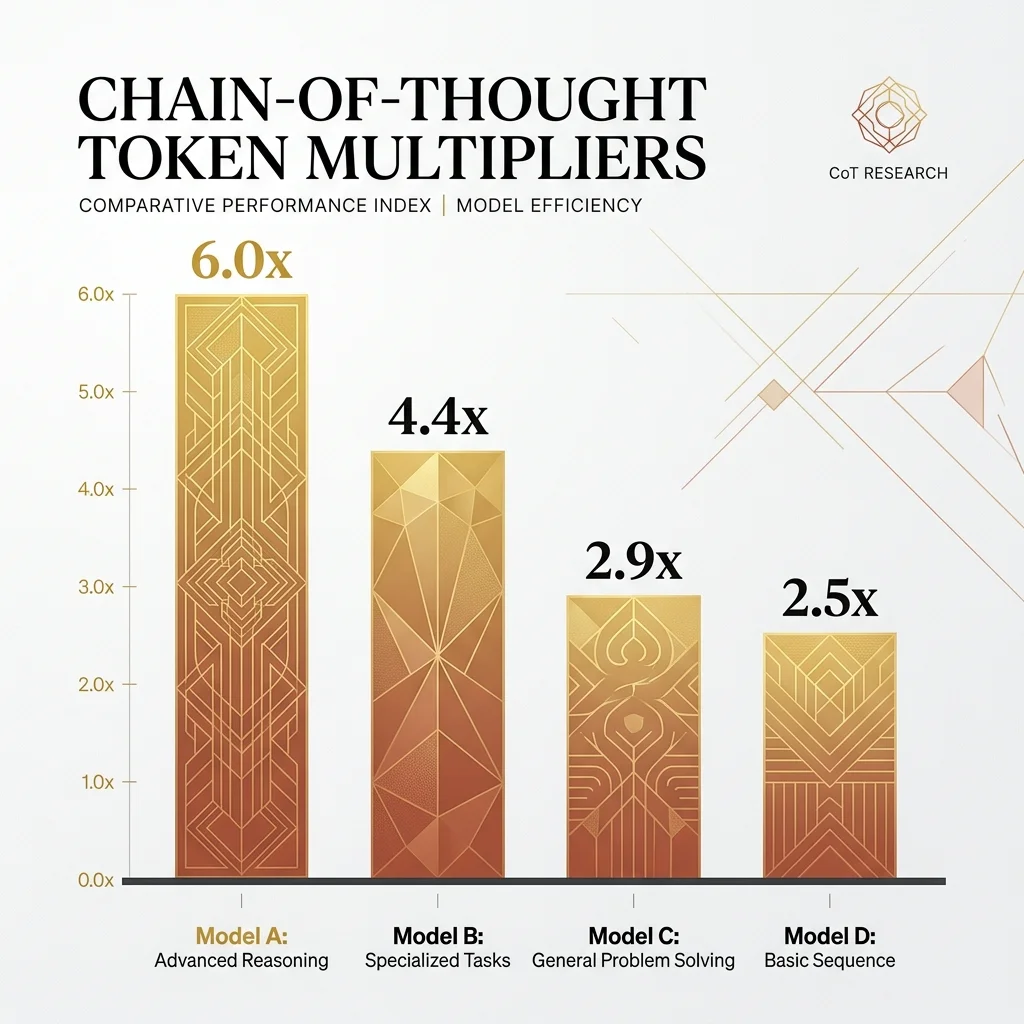
Per call, these numbers look trivial. But scale matters:
- Classification pipeline processing 50,000 items/day: $40/day direct vs $175/day with CoT — $49,000/year difference for identical accuracy.
- Creative content generation at 1,000 pieces/day: $3.50/day vs $7.20/day — less dramatic per call, but still 2x cost for worse output.
- Customer support classifier routing 100,000 tickets/day: CoT adds $1,900/month in API costs with zero accuracy improvement.
Three rules of thumb for cost:
- If the task doesn't require multi-step reasoning, CoT is pure waste.
- If CoT improves accuracy, the cost is usually justified — accuracy losses downstream are more expensive than tokens.
- If you're not measuring accuracy, you don't know which camp you're in.
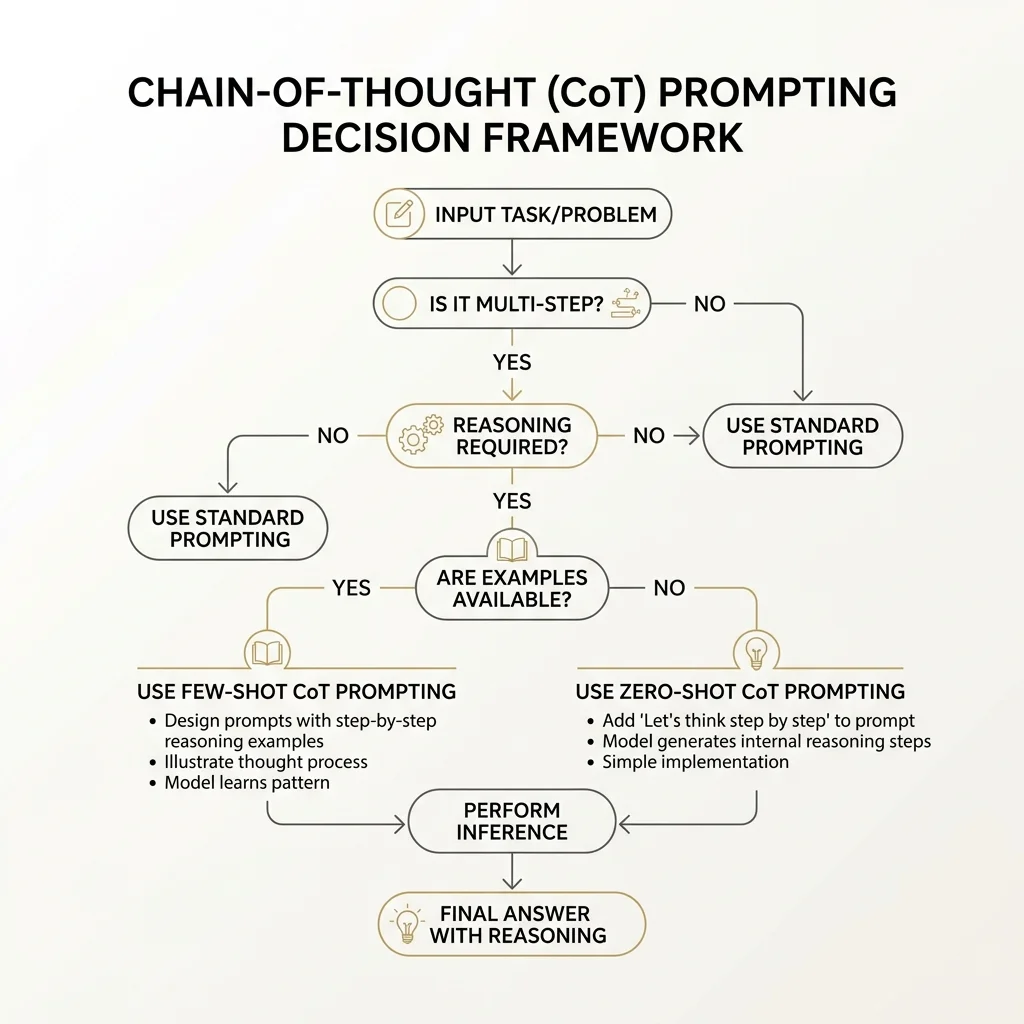
The Decision Framework
Here's a simple heuristic for your prompts:
Is the task multi-step?
│
├── NO → Skip CoT
│ (classification, factual recall, simple generation)
│
└── YES → Does it require explicit reasoning?
│
├── NO → Skip CoT
│ (creative writing, summarization,
│ open-ended brainstorming)
│
└── YES → Use CoT
(arithmetic, logic, multi-criteria
analysis, code debugging, planning)
Green flags for CoT:
- The answer depends on intermediate calculations
- Multiple constraints need to be satisfied simultaneously
- The reasoning chain is more valuable than the final answer (e.g., you need to audit or verify)
- The task has a single correct answer but a high error rate without reasoning
Red flags for CoT:
- The task is pattern recognition or classification
- The output quality depends on voice, flow, or creative instinct
- The model already gets it right >95% of the time without CoT
- You're optimizing for latency or cost over marginal accuracy gains
Gray zone — test both:
- Code generation: CoT helps with algorithmic problems (sorting implementations, dynamic programming), hurts for boilerplate (CRUD endpoints, config files). Generate both versions and benchmark.
- Summarization: CoT sometimes produces more structured summaries, sometimes over-fragments the content. Test on your specific document type.
The only reliable way to know is to run both versions on a small evaluation set. Ten representative inputs, direct vs CoT, score the outputs. The results are often surprising — and usually not what the research papers predict.
Key Takeaways
- CoT is not a default. It's a targeted tool for tasks that require explicit step-by-step reasoning.
- On math and logic, CoT delivers a 20-30% accuracy improvement — worth the 2.5-3x token cost.
- On classification, creative writing, and factual recall, CoT either wastes tokens, degrades output quality, or invents plausible-sounding but unreliable reasoning.
- The token multiplier ranges from 2x to 8x depending on task type. Multiply by your daily volume before deciding.
- Test both versions. Ten examples, direct vs CoT, measure accuracy. The answer isn't in a paper — it's in your data.
If CoT isn't cutting it for your use case, agentic prompting patterns add planning, tool use, and self-correction on top of basic reasoning — sometimes that's the leap you actually need.