Monday, June 15, 2026
DiffusionGemma: How Text Diffusion Breaks the LLM Memory Wall
Posted by

Every text-generation model you have used — GPT-4, Claude, Gemini, Llama — generates text the same way: one token at a time, strictly left to right. This autoregressive loop is the bedrock of modern LLMs, but it hides a hardware tax that becomes painfully obvious when you run models locally.
The GPU tensor cores, the hardware actually doing the matrix math, sit idle up to 90% of the time during single-user inference. They are starved for data while the entire 26-billion-parameter weight set is shuttled across the memory bus — for every single token.
DiffusionGemma, released by Google DeepMind on June 10, 2026 under the Apache 2.0 license, abandons this sequential paradigm entirely. Instead of typing tokens one at a time like a typewriter, it starts with a canvas of random tokens and refines the entire block in parallel — like a photo editor working on a rough draft.
The result: 700+ tokens per second on an RTX 5090, 1,000+ on an H100, and up to 2,000 on an NVIDIA DGX — all on a 26B-parameter model that fits in 18-24 GB of VRAM when quantized.
This post covers how it works under the hood, the benchmark trade-offs, the exact vLLM serving command, and what it means for developers building agents and coding tools.
The Memory Wall: Why Autoregressive LLMs Are Slow
The fundamental bottleneck in autoregressive inference isn't compute — it's memory bandwidth.
Here's what happens every time a transformer generates a token:
- The GPU loads the entire weight set from VRAM to compute registers
- Runs one forward pass through the transformer
- Produces one token
- Appends it to the context
- Goes back to step 1
For a 26B-parameter model, that's gigabytes of data crossing the bus for every single token. Modern tensor cores can compute matrix operations faster than the bus can deliver weights, so they spend most of their time waiting.
The numbers tell the story:
| Bottleneck | Utilization |
|---|---|
| GPU compute cores (tensor cores) | 10-20% utilized |
| Memory bus | 80-90% saturated |
| Time spent loading weights per token | ~90% of total |
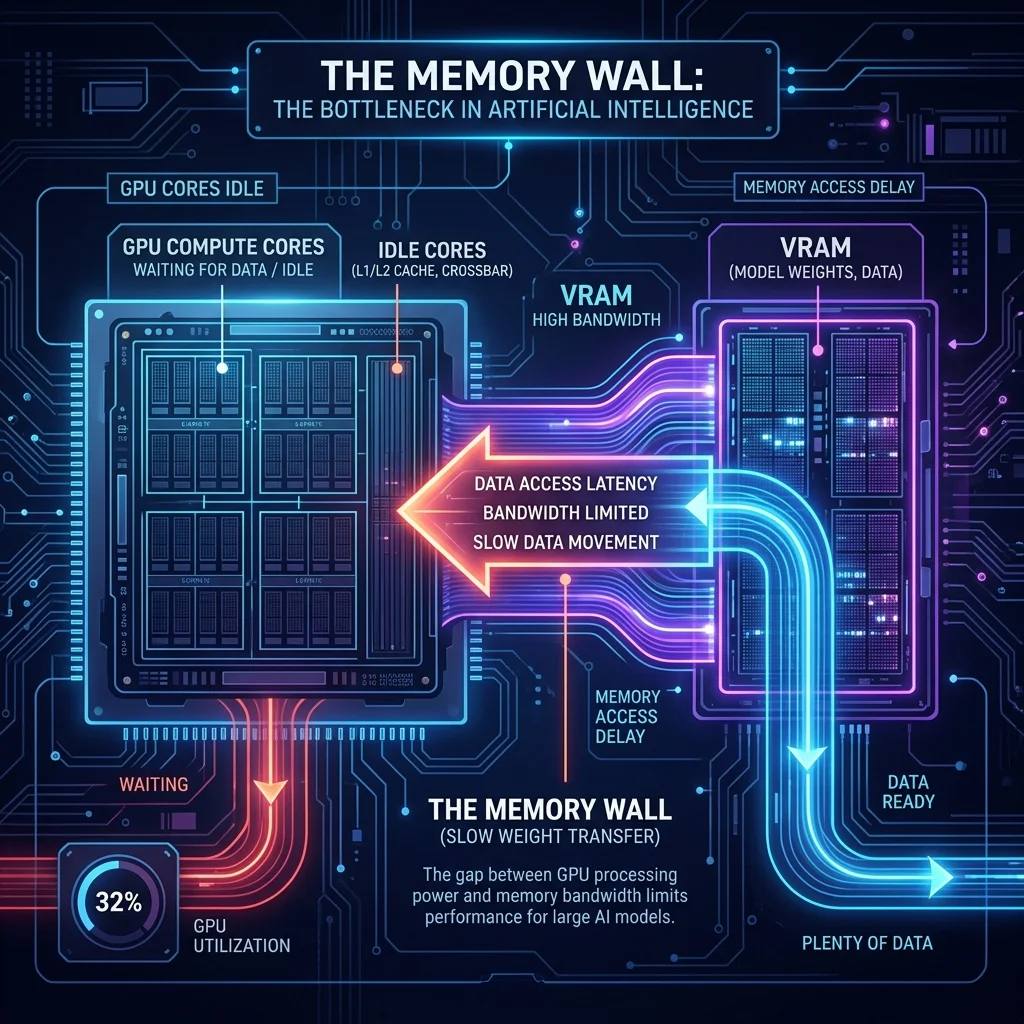
This is the Memory Wall. It's not solvable with better GPUs or clever batching for single-user local inference — it's a fundamental architectural constraint of the autoregressive loop.
The Reversal Curse
Beyond hardware, sequential generation introduces a cognitive flaw: if a model learns "A is the mother of B" during training, it often fails to answer "Who is B's mother?" in inference. The causal attention mask prevents the network from ever seeing tokens to the right of the current position during training, creating a directional bias in knowledge representation.
DiffusionGemma addresses both problems at once because it doesn't generate sequentially at all.
How DiffusionGemma Works
DiffusionGemma is a 26-billion-parameter Mixture-of-Experts (MoE) model built on the Gemma 4 backbone. It activates only 3.8B parameters per token, meaning inference runs at roughly the speed of a 4B-parameter dense model despite the 26B footprint.
Architecture at a Glance
| Specification | Value | Why It Matters |
|---|---|---|
| Total Parameters | 25.2B | Full weight set stored in VRAM |
| Active Parameters per Token | 3.8B | MoE routing fires only 3.8B per token; inference speed ≈ 4B dense model |
| Total Experts | 128 | Router selects from 128 specialized sub-networks |
| Active Experts per Token | 8 + 1 shared | 8 routed + 1 always-on shared expert for global context |
| Layers | 30 | Shallower than comparable dense models, compensated by expert width |
| Vocabulary | 262,144 tokens | Large vocab improves multilingual coverage |
| VRAM (FP8 / NVFP4 quantized) | 18-24 GB | Fits RTX 4090 and RTX 5090 with headroom for 256K context |
| Block (Canvas) Size | 256 tokens | Each parallel denoising pass processes 256 tokens at once |
Uniform State Diffusion
Instead of predicting the next token, DiffusionGemma uses Discrete Denoising Diffusion Probabilistic Models (D3PM) — the text equivalent of how image diffusion models like Stable Diffusion work.
The problem: there's no smooth mathematical midpoint between "cat" and "dog" in discrete token space. You can't add Gaussian noise to individual words the way you can to pixels.
DiffusionGemma solves this with Absorbing State (Masking) Diffusion. During training, tokens are randomly replaced with a [mask] token. The model learns to run this corruption process in reverse:
Step 0: The quick brown fox jumps over the lazy dog (clean text)
Step 1: The [mask] brown fox jumps [mask] the lazy dog (30% masked)
Step 2: [mask] [mask] brown [mask] [mask] [mask] the [mask] [mask] (70% masked)
Step 3: [mask] [mask] [mask] [mask] [mask] [mask] [mask] [mask] [mask] (100% masked)

During inference, the model starts from Step 3 (a fully masked 256-token canvas) and iteratively denoises the entire block in parallel. Each pass uses bidirectional attention — every token on the canvas can attend to every other token simultaneously, not just tokens to its left.
The denoising process uses an entropy-bound sampler:
- Temperature schedule: starts at 0.8 for broad semantic exploration, scales down to 0.4 to lock in final selections
- Entropy filtering: tokens the model is certain about are locked in permanently; uncertain tokens are re-noised and re-evaluated
- Early stopping: generation halts when average canvas entropy drops below 0.005 and two consecutive passes yield identical predictions. For structured tasks like code or JSON, this often happens in 12-16 steps
Block Autoregressive System
For sequences longer than 256 tokens, DiffusionGemma uses a Block Autoregressive approach:
Phase 1 — Prefill / Commit (causal attention): Ingests the user prompt (or a completed 256-token canvas) using standard causal attention and writes to the KV cache. This runs once for the initial prompt, then once per block to commit each finalized canvas.
Phase 2 — Denoising (bidirectional attention): A new 256-token canvas is initialized with masked tokens. Bidirectional attention allows every token on the canvas to attend to every other canvas token and to the KV cache of previously committed history. Parallel refinement passes run until the entropy-bound sampler declares convergence.
This hybrid approach combines the parallel speed of diffusion for blocks with the sequential stability of autoregressive models for long-form text.
Serving DiffusionGemma
Google worked with the vLLM team to integrate DiffusionGemma at day zero. The integration repurposes vLLM's speculative decoding infrastructure — the entire 256-token canvas is treated as a single massive draft block. During intermediate denoising steps, the sampler flags canvas tokens as "rejected," holding the KV cache fixed and immediately re-queuing the same block for refinement.
Deploy with vLLM
vllm serve google/diffusiongemma-26B-A4B-it \
--max-model-len 262144 \
--max-num-seqs 4 \
--gpu-memory-utilization 0.85 \
--attention-backend TRITON_ATTN \
--generation-config vllm \
--hf-overrides '{"diffusion_sampler": "entropy_bound", "diffusion_entropy_bound": 0.1}' \
--diffusion-config '{"canvas_length": 256}' \
--enable-chunked-prefill
Key flags explained:
--max-num-seqs 4: Diffusion is compute-bound, so vLLM batches fewer sequences than an autoregressive model. Four parallel diffusion canvases saturate an H100's compute.--hf-overrides: Configures the entropy-bound sampler and threshold. Theentropy_boundsampler halts when the canvas is stable. Lower entropy thresholds produce more refined output at the cost of more denoising steps.--diffusion-config: Sets the canvas length. 256 is the default and recommended. Larger canvases increase the parallel workload per step but reduce the number of block transitions for long sequences.--enable-chunked-prefill: Required for vLLM to handle the alternating causal/bidirectional attention pattern efficiently.
Hardware Requirements
| GPU | Quantization | Tokens/sec | VRAM Used |
|---|---|---|---|
| NVIDIA H100 | FP8 | 1,000+ | ~24 GB |
| NVIDIA RTX 5090 | NVFP4 | 700+ | ~20 GB |
| NVIDIA RTX 4090 | NVFP4 | 500+ | ~20 GB |
| NVIDIA DGX Spark | - | ~150 | - |
| NVIDIA DGX (8×H100) | FP8 | 2,000+ | - |
Other Deployment Options
- Hugging Face Transformers: Direct integration available, though vLLM is recommended for production
- SGLang: Supported with dedicated backend
- MLX: Apple Silicon support via MLX community collection
- NVIDIA NIM: Containerized deployment via NVIDIA AI Enterprise
- Google Cloud Model Garden: One-click deploy on GCP
- Unsloth: Efficient fine-tuning support
- NVIDIA NeMo: Custom model training and deployment pipeline
Benchmark Analysis
This is where the story gets nuanced. DiffusionGemma dominates on generation speed but trails frontier autoregressive models on zero-shot complex reasoning.
DiffusionGemma vs. Gemma 4 (Autoregressive)
| Benchmark | Focus | DiffusionGemma 26B | Gemma 4 26B (AR) | Gap |
|---|---|---|---|---|
| MMLU Pro | Complex multilingual Q&A | 77.6% | 82.6% | -5.0% |
| MMMU | Multimodal contextual Q&A | 81.5% | 86.3% | -4.8% |
| AIME 2026 (no tools) | Advanced mathematics | 69.1% | 88.3% | -19.2% |
| LiveCodeBench v6 | Software engineering | 69.1% | 77.1% | -8.0% |
| BigBench Extra Hard | Intricate linguistic logic | 47.6% | 64.8% | -17.2% |
The 19-point gap on AIME 2026 and 17-point gap on BigBench Extra Hard are not bugs — they are architectural consequences. Autoregressive transformers build logical chains step-by-step, with each token strictly conditioned on a finalized history. Diffusion models evaluate the entire block simultaneously. This is excellent for global syntax and structure, but it loses the thread of multi-step sequential reasoning in zero-shot settings.
The Sudoku Case Study: Latent Spatial Reasoning
Zero-shot benchmarks don't tell the full story. Google fine-tuned DiffusionGemma on Sudoku puzzles — a strict multivariable constraint problem that traditional LLMs consistently fail because they can't plan for future cells while filling the current one.
| Model | Success Rate | Steps to Solve |
|---|---|---|
| DiffusionGemma (base, zero-shot) | ~0% | Timed out at 48 steps |
| DiffusionGemma (SFT-tuned) | 80% | 12 steps |
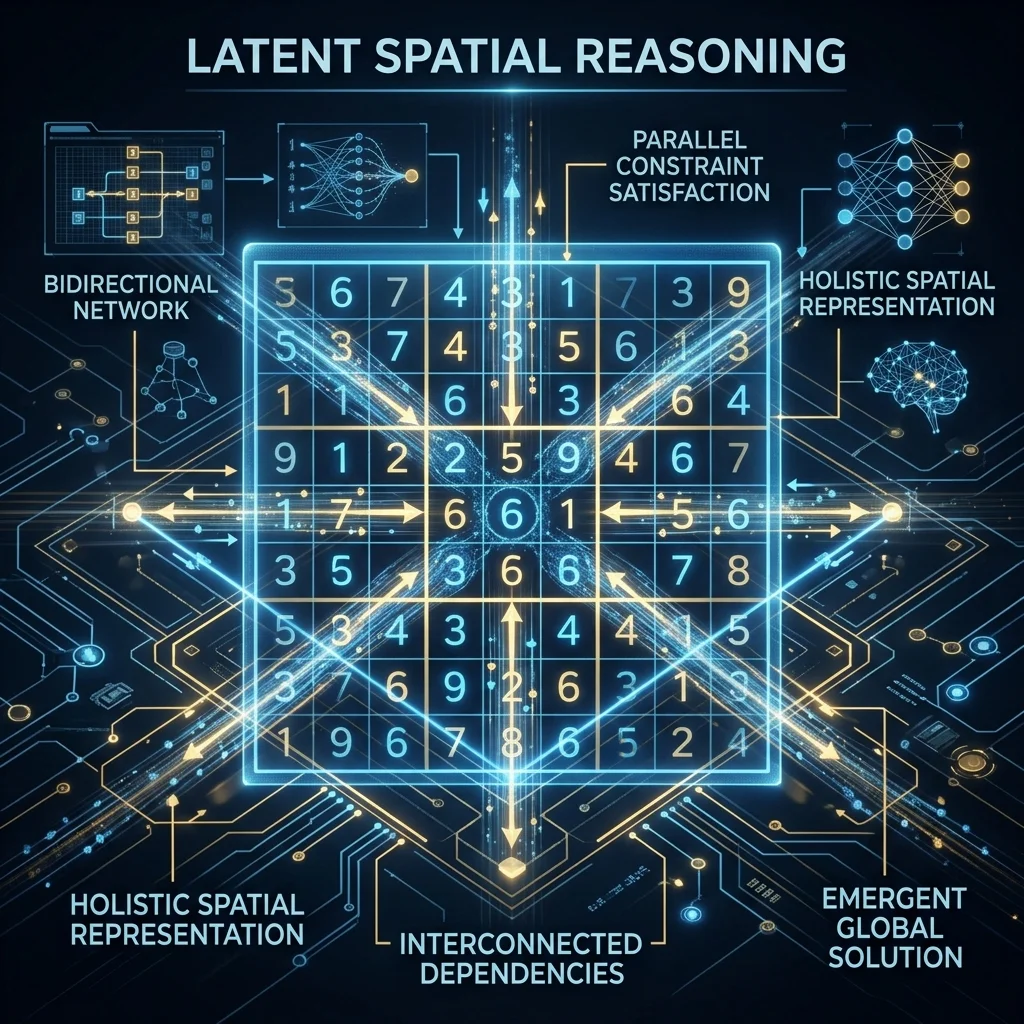
Bidirectional attention makes DiffusionGemma a fundamentally different tool for constraint-heavy tasks. An autoregressive model tackling Sudoku writes digits left to right — the first cell constrains the second, which constrains the third, etc. If cell 9 contradicts cell 1, the model has no mechanism to go back and fix it. DiffusionGemma evaluates the entire 81-cell grid simultaneously in each denoising pass. Errors in one corner get corrected because information flows symmetrically.
This suggests that while zero-shot math benchmarks show lower scores, targeted fine-tuning unlocks structural reasoning that autoregressive models cannot match.
What This Means for Developers
1. Code Infilling Becomes Near-Instant
Tools like Cursor and Windsurf rely on fill-in-the-middle: ingest the top half of a file, guess the middle, align with the bottom half. Traditional models use left-to-right context only, leading to duplicated brackets and broken indentations. DiffusionGemma sees both prefix and suffix simultaneously and refines the blank block until the syntax fits perfectly.
At 700+ tokens/sec locally, real-time code infilling becomes practically instantaneous.
2. Structured JSON Generation for Agent Routing
Autonomous agents spend significant compute on routing — parsing natural language inputs into structured JSON payloads for tool calls. Autoregressive models are prone to truncating trailing curly braces when context limits are reached, breaking the parser and stalling the agent loop.
DiffusionGemma enforces structural parameters across the entire canvas simultaneously. Schemas open and close correctly because the model can attend to the opening bracket while generating the closing one. This makes it an excellent candidate for intent router or structured output tasks in agentic workflows.
3. Prompt Engineering Changes — No Chain-of-Thought (in the Traditional Sense)
DiffusionGemma does not generate tokens left to right, which means chain-of-thought prompting works differently. When you write "Let's think step by step..." on an autoregressive model, each subsequent token is conditioned on all previous tokens, building a reasoning chain.
With diffusion, the entire response is refined in parallel. There is no "step-by-step" in the same sense — the model evaluates the full response simultaneously. Early results suggest:
- Better at constraint satisfaction (fill-in-the-blank, template completion, structured output)
- Worse at multi-step logical deduction in zero-shot settings
- Fine-tuning is more important than prompt engineering for unlocking capabilities
If diffusion-based text models become mainstream for agent development, the prompt engineering playbook will need to shift from "reasoning chain design" to "constraint and structure specification".
4. Local AI Economics Change
Because DiffusionGemma is compute-bound rather than memory-bound, its performance scales with raw GPU TFLOPS — exactly what consumer gaming GPUs deliver. An RTX 5090 achieves 700+ tokens/sec with DiffusionGemma. The same card running Llama 4 70B (autoregressive) would struggle to hit 50 tokens/sec at comparable quality.
This shifts the economics of local AI: you no longer need server-grade memory bandwidth to get high throughput. Consumer hardware becomes viable for production-quality local inference.
When to Use DiffusionGemma (and When Not To)
Use It For
- Code infilling and editing — real-time fill-in-the-middle
- Structured JSON / tool call generation — agent routing and structured output
- Template completion and constrained generation — forms, schemas, configs
- Offline / privacy-critical applications — runs well on consumer GPUs
- High-throughput local inference — where latency per request matters more than reasoning depth
- Tasks with global structural constraints — Sudoku, constraint satisfaction, formatting
Don't Use It For (Yet)
- Multi-step mathematical reasoning — autoregressive models still dominate AIME-level math
- Long chain-of-thought deduction — the parallel canvas can lose the thread of sequential logic
- Tasks requiring deep zero-shot reasoning — MMLU Pro and BigBench gaps are real
- Replacing a general-purpose reasoning agent — this is a specialized co-processor, not a frontier replacement
The Hybrid Future
The most likely industry direction over the next 2-3 years is architectural hybridization: inference engines that route reasoning tasks to autoregressive models and speed-critical structure tasks to diffusion models within a single request. Google's Block Autoregressive approach — mixing causal encoding with parallel diffusion canvases — is an early production version of this.
Pitfalls
1. Quantization Is Required for Consumer GPUs
The full-precision 26B model needs ~52 GB of VRAM. FP8 quantization gets you to ~24 GB. NVIDIA's 4-bit NVFP4 format brings it to ~18 GB. Without quantization, consumer GPUs cannot run DiffusionGemma. Make sure your vLLM or inference framework includes quantization support.
2. The Canvas Size Is Not Configurable Above 512
While the default canvas is 256 tokens, the architecture supports larger canvases only up to about 512 tokens before quadratic attention costs erode the speed advantage. For long generations, the model auto-commits and creates new canvases, so you don't lose output length — but the generation granularity is always 256-token chunks.
3. vLLM Batch Size Must Be Kept Low
DiffusionGemma is compute-bound, meaning it saturates the GPU differently than autoregressive models. From the developer guide: --max-num-seqs 4 is the recommended maximum for an H100. Trying to batch 16+ sequences will overflow VRAM because each diffusion canvas carries the full bidirectional attention cost.
4. First-Token Latency Is Higher Than Autoregressive
DiffusionGemma is not optimized for single-token streaming applications. The first output block requires multiple denoising steps (12-48, depending on entropy) before any text is produced. For use cases that need immediate first-token response (chat, streaming), autoregressive models are still preferable.
5. Fine-Tuning Is Almost Required for Complex Tasks
The zero-shot AIME gap (69.1% vs. 88.3%) shows that DiffusionGemma's out-of-box reasoning is weaker than Gemma 4 AR. However, the Sudoku case study (0% → 80% with SFT) proves that targeted fine-tuning can unlock capabilities. Plan for a fine-tuning step if you need DiffusionGemma for complex tasks — don't expect zero-shot parity with autoregressive models.
6. Not All Inference Frameworks Support Diffusion
Day-zero integration with vLLM is solid, but support in other frameworks varies. Verify your serving stack supports the bidirectional attention pattern before committing to a deployment architecture.
Getting Started
- Download the weights: Hugging Face — google/diffusiongemma-26B-A4B-it (Apache 2.0)
- Read the architecture guide: Google AI — Diffusion in Text Generation Explained
- Visual guide: Maarten Grootendorst — Visual Guide to DiffusionGemma
- Fine-tuning recipes: GitHub — google-deepmind/gemma/diffusion (uses Hackable Diffusion, a JAX research toolbox)
- Unsloth fine-tuning: Unsloth Docs — DiffusionGemma
- NVIDIA NIM deployment: NGC — diffusiongemma-26b-a4b-it
- Google Cloud deployment: Model Garden — DiffusionGemma
- vLLM release notes: vLLM Blog — DiffusionGemma integration
Key Takeaways
-
The Memory Wall is real. Autoregressive models reload tens of gigabytes of weights per token, leaving GPU compute idle up to 90% of the time on single-user local inference.
-
Discrete diffusion shifts the bottleneck. By generating 256 tokens in parallel, DiffusionGemma makes inference compute-bound instead of memory-bound, saturating tensor cores that would otherwise sit idle.
-
Bidirectional attention eliminates the reversal curse. Seeing the full context simultaneously fixes the directional knowledge asymmetry inherent to causal models.
-
Speed comes with a reasoning trade-off. Zero-shot math and logic scores drop measurably — but targeted fine-tuning unlocks spatial and structural reasoning that autoregressive models cannot match.
-
Consumer hardware viability changes the economics. 700+ tokens/sec on an RTX 5090 makes high-quality local inference practical without enterprise GPUs.
-
Expect hybridization, not replacement. The most likely future is inference engines that route between autoregressive reasoning and parallel diffusion blocks depending on the task.